Fintech companies aim to modernize access to financial information and services, and commonly create applications that require interacting with third-parties such as banks. Given the slow adoption of standards and public APIs, the current landscape presents particular technical challenges that sometimes require creative solutions.
This lack of open APIs leads to fintech applications having to scrape data to access the information available at the third-party financial institutions. Scraping will usually require the application to know the third-party user credentials (username and password), so the different flows (login, query profile, execute transaction, etc.) can be simulated. From a security perspective, having to be a custodial of these credentials presents a big risk, so designing an application that incorporates proper controls to safeguard this piece of information is key.
In this blog post, we will discuss one of the most common fintech security challenges: how to securely store and use these user credentials in the context of a generic fintech application that needs to interact with a third-party data provider. We won’t cover extensively all the relevant appsec aspects, but rather focus on the specific requirements for storing the credentials.
Whenever we think about storing credentials, the first thing that comes to mind is the login use case, which is solved using hashing algorithms to avoid storing the passwords in cleartext, and making them hard (or practically impossible) to retrieve if the hashes are compromised. However, in the context of the application we will discuss, hashing will not work as access to the plaintext credentials is required.
To mitigate the risk of storing the credentials in a retrievable way, they will need to be stored encrypted, and strict controls on encryption keys enforced. Encrypting data is the go-to recommendation, but even though It may sound straightforward, there are a lot of factors that need to be considered and a lot of ways in which it can go wrong. For example, the following questions will need to be answered:
Where will the credentials be stored?
What encryption algorithms and modes of operation will be used?
Who (person or service) will have access to the encryption keys?
How do you detect if a key was compromised?
We will try to offer some insight into the decision process that goes behind when thinking about a possible solution that is both practical and secure. It is by no means the only way to go about this, just a reasonable one.
In this section we will provide practical examples on how to approach the problem and existing services that can be used.
Because we aim to be practical, we will leverage cloud infrastructure and services, in particular AWS. Most cloud providers offer similar solutions to this problem, so the general idea should be applicable without major modifications. Even if the application will be hosted in your own infrastructure, considering using the key management cloud services might be a good idea anyway, as implementing all the required controls manually can require significant effort and is prone to error.
Following we’ll explain in more detail the security considerations that need to be taken into account for each step of the credential lifecycle, from provisioning to usage.
This refers to the process where the end-user sets up their account on the application, which requires them to hand off their credentials. This is when the lifecycle of this piece of sensitive information within your application begins, therefore the security protocol needs to kick in.
There are some specific things that need to be considered as the credentials go through the client application to their final storage location:
Principle of least privilege
This is one of the most common security principles, and it also applies to this situation. Whenever possible, we should ask users to provide credentials with the least privileges possible. Sometimes financial institutions allow the creation of read-only users, which help reduce the associated risk with the credentials, by limiting their capabilities (e.g. not possible to transact with them).
Protection of credentials when in transit
Another important aspect is protecting these credentials while they are being transmitted through the internet and internal networks.
The solution for this is pretty standard, and consists of using TLS (Transport Layer Security) between clients (browser and mobile apps) and servers, and even between server to server communications. TLS v1.3 should be preferred, along with strong cipher suites. In mobile applications, controls like certificate pinning can offer additional protections. Also, consider using cloud edge services that already solve this, like AWS ELB or Cloudflare.
Further information regarding how to securely set up TLS can be found here.
Once the credentials are received from the user, they’ll need to be stored for long term use by the backend, so how they are stored is one of the most important aspects in this context in terms of security. We’ll go over a few of the questions that may arise and a possible answer.
Where and how will the credentials be stored?
Credentials can be stored in normal databases (after being encrypted), or in dedicated secret storage solutions, such as AWS Secrets Manager (SM), Hashicorp Vault, among others.
The decision depends on different factors, scalability and cost being some of the most important. Typically, managed secret storage solutions limit the amount of objects that can be stored, and can even have extra costs associated with them. For instance, AWS SM can normally store up to 100,000 secrets, and storing each secret costs $0.40 monthly, so costs can quickly add up.
Another thing to consider is the intended use case. Managed secret storage solutions are normally intended to store application secrets, like third-party service API keys, database passwords, and other secrets used by the application in runtime; and not end-user data.
Therefore, for the purpose of this example, we will move forward with storing the encrypted credentials in a normal database, and focus on how to solve the cryptographic operations in the application-side, and key management leveraging a service provided by a cloud vendor.
Where and how will the keys be stored?
Handling encryption keys requires various controls that are both technical and operational in nature, to minimize the risk of their compromise. For example, you will need a dedicated storage location, with proper logical and physical access controls, as well as documented procedures and policies to establish how the key lifecycle is managed.
Having to do all this manually may result in significant overhead in the day to day activities, making teams resort to more “practical” solutions like sharing and hardcoding the encryption keys. Other in-house solutions might involve an HSM device, which probably represents a significant cost for most start-ups.
Good news is there are dedicated solutions designed to solve this specific problem. Most cloud providers offer services to handle this, for instance: HashiCorp Vault, AWS (and Google) KMS (Key Management System) and CloudHSM (Hardware Security Module). These have the benefit of providing simple interfaces, transparently taking care of the generation and rotation processes, as well as having compliant deployments and controls.
In track with our AWS-flavored example, we will leverage the services offered by AWS to store encryption keys. So, should we use KMS and/or CloudHSM? The following diagram illustrates the main possible architectures involving these services:
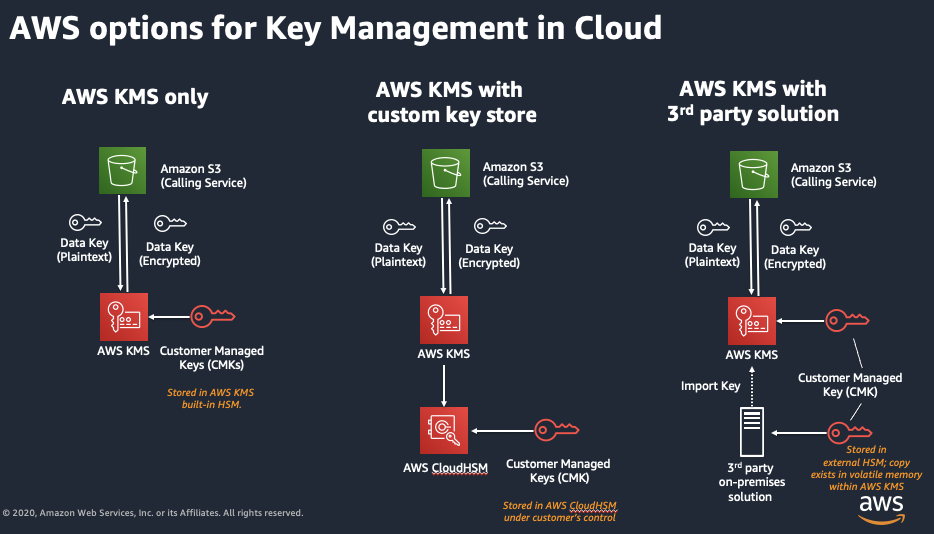
All these architectures use the KMS APIs, but they differ on where the keys are stored:
AWS KMS only: stores keys in a shared KMS-managed HSM cluster
AWS KMS with custom key store: stores keys in a dedicated CloudHSM instance
AWS KMS with 3rd party solution: uses a third-party HSM (normally hosted on-premises) to store keys
So what’s the real difference between these alternatives? The main difference relies on how much control you have over the keys, and the physical and logical isolation of the HSM. If you rely on a fully KMS-managed solution (AWS KMS only), the keys will be stored in a pool of AWS-managed HSMs. This does not mean that your keys will be shared or potentially accessible by other AWS customers or employees, but rather they are responsible for the logical and physical controls.
On the other hand, CloudHSM (AWS KMS with custom key store) offers managed single-tenant devices, allowing you to control a single HSM instance dedicated to your account. However, from a compliance perspective, both the first and second alternatives offer similar controls regarding logical access, but differ in their physical security controls. KMS is FIPS 140-2 Level-2 certified and Cloud HSM is Level-3. The differences between the levels are mostly in the physical security requirements.
Finally, in the context of a fintech startup, going for a self-managed HSM solution, either the CloudHSM or the on-premise HSM (AWS KMS with 3rd party solution), can be very costly and may not offer significant benefits. So, even though each company will need to do their own risk assessments, it is reasonable to adopt a solution based on managed-KMS from a security perspective.
Where will the encryption and decryption take place?
AWS KMS offers Encrypt and Decrypt operations that could be considered encryption-as-a-service. In other words, you indicate which key to use, plus the plaintext, and KMS will return the encrypted data (and the opposite for decrypting).
This is a very simple solution, given that it removes the need for having to deal with researching, choosing and correctly using third-party cryptographic libraries. However, it has a few disadvantages:
If we used the encryption and decryption operations provided by KMS, we would be adding another responsibility to KMS, when we only want it to solve the key management problem.
Additionally, AWS KMS is restricted to a maximum plaintext size of 4,096 bytes, so it’s not possible to encrypt large amounts of data.
Finally, AWS charges a fee for each request to the KMS API, so if the volume of operations is very high costs can add up.
Taking into consideration the points above, we’ll develop a solution that uses KMS only for key management, and performs the encryption and decryption operations locally in the application. The secrets will be stored in a database, each encrypted with a different data encryption key (DEK) based on the envelope encryption concept.
What libraries and algorithms should be used for encryption?
The choice of algorithms can deeply impact the overall security of the solution, and making the decision can be overwhelming, since it requires specific skill sets, in particular a good understanding of applied cryptography. Because of this, it is best to try to avoid this problem completely, and to rely on battle-tested and industry-accepted implementations.
To reinforce a well known principle, you should never roll your own encryption. It is very easy to introduce implementation mistakes, so you should always rely on trusted libraries.
In this example, we’ll be leveraging the AWS Encryption SDK, which provides crypto implementations and easily integrates with KMS, providing extra security features such as envelope encryption and secure defaults. In case you’d rather not use this SDK, there are other libraries, such as NaCL and libsodium.
Both these options provide secure defaults, so you won’t need to think about what specific algorithms to choose. However, if for some reason you need to use specific algorithms, you may find the “Cryptographic Right Answers” article from Latacora to provide valuable insight.
We discussed the different aspects of the solution individually, and we’ll now see how it all fits together. To state it in one paragraph, the idea is the following:
Credentials are encrypted in a database using envelope encryption, the master key is stored in AWS KMS on a KMS-managed HSM cluster, and unique data keys used for each user credential. Encryption and decryption operations are performed with the AWS Encryption SDK using its default algorithms.
Now that we know how the solution works on a high-level, we’ll describe how it works in practice. The following diagram shows the sequence of operations that will take place in the provisioning (first time storage) and retrieval (for use by the backend) processes of the credentials:
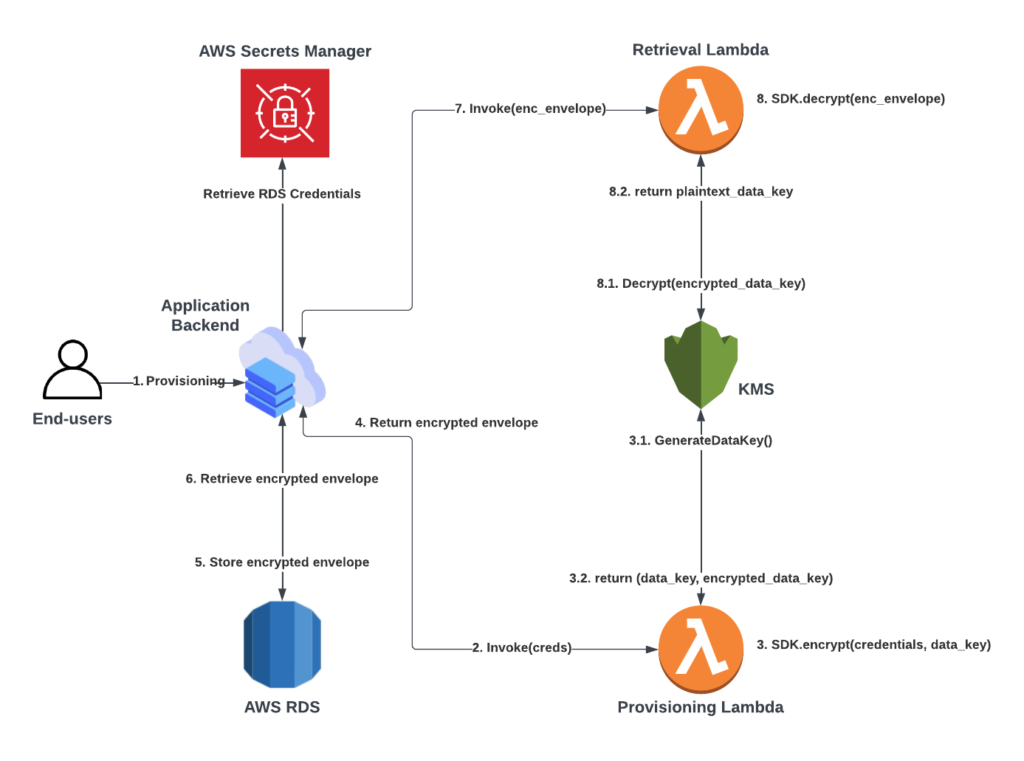
The description of each of the steps (represented by the numbered arrows) is the following:
Provisioning
An end-user provides the credentials for their financial institution. There should be a process to validate these credentials against the financial institution (not included in the diagram)
The application invokes the Provisioning Lambda, providing the credentials as a payload
The Provisioning Lambda calls the encrypt() function of the AWS Encryption SDK, which internally will do the following:
Generate a data key by calling KMS GenerateDataKey
KMS returns the plaintext and encrypted data key
The credentials will be encrypted using the data key
The Provisioning Lambda returns the encrypted credentials within an encryption envelope to the application’s backend. The envelope includes the encrypted credentials and the data key used to encrypt them
Provisioning Lambda stores the envelope in the database
Usage
The application retrieves the envelope from the database
The application invokes the Retrieval Lambda, providing the envelope as a payload
The Retrieval Lambda calls the decrypt() function of the AWS Encryption SDK, which internally will do the following:
Decrypt the encrypted data key by calling KMS Decrypt
KMS returns the plaintext data key
The SDK uses the key to decrypt the encrypted credentials
As outlined above, there were two API calls to the KMS service: one to GenerateDataKey, and another to Decrypt. Based on the current KMS service pricing, the cost of 10,000 requests is $0.03 (the first 20,000 are free), so in most cases the costs should be reasonable.
You may be wondering why we included Lambda functions as part of the architecture. There are several reasons for this, based around the concept of separation of duties, with the goal of achieving the following:
The backend should not have access to the encryption keys
The Provisioning Lambda should only be able encrypt, but not decrypt, user credentials
The Retrieval Lambda should only be able to decrypt the credentials, but not encrypt new ones (if possible, only one or n decryption operation(s) per invocation)
The compromise of the backend or the database does not result in user credentials being leaked
In summary, we described the thought process that took place in order to design a reasonably simple architecture, which balances the different tradeoffs, and avoids having to deal with complicated cryptographic decisions.
Apart from the specifics on how to store the credentials, we need to pay attention to security issues that could affect the application itself and its underlying infrastructure (i.e. AWS environment, databases, etc.).
For example, imagine a scenario in which an attacker makes a wire transfer targeted to an end-user of your application, containing an attack payload in the description field. If the Retrieval Lambda were vulnerable to, say, a JSON insecure deserialization vulnerability when parsing the transfer description, the attacker could achieve code execution within the Lambda context. Given that the Lambda would be executing with a role that had permission to access the decryption key, it would then be possible for the attacker to compromise cleartext credentials for the target user only (the credentials provided as a payload when the Lambda was invoked).
To further elaborate on the previous scenario, imagine that in addition to the application-level vulnerability, the role used for the Lambda execution was overly scoped. This could result in attackers escalating privileges within the AWS account, and further compromising the AWS services and resources. Therefore, it is also important to implement security best practices specific to the AWS environment to reduce the impact of an application-level vulnerability. For instance, IAM policies should be scoped to the minimum set of required permissions, MFA should be enabled throughout the account, and resources should be configured so that information is protected both when in transit and at rest.
This reinforces the importance of maintaining good appsec practices, ensuring that proper controls are in place, and that the applications are regularly tested.
Finally, we should highlight the importance of logging and monitoring as it will keep track of the usage of encryption keys, to detect any behavior outside the norm. For instance, it would be interesting to log actions such as the following:
Whenever encrypted credentials are retrieved
Whenever encryption keys are retrieved
Whenever encrypted credentials were decrypted for usage
Unusual amount of decryption operations
Decryption operations outside of expected hours
We presented a potential solution to one of the most common data security issues faced by fintech companies, regarding how to securely store user credentials in a retrievable way, and walked through the process behind finding a good architecture and implementation of the cryptographic aspects. The reasoning was based on accepted principles and best practices, and also considering tradeoffs, such as the associated effort, costs and technical complexities.
General application and infrastructure security aspects were not thoroughly covered, but are indeed as relevant as the credential storage specific controls. Some attack scenarios may be hard to predict (such as the one described above), so focusing on having good encryption or well-scoped IAM policies may not be enough. Having regular security tests performed on the final deployment is key to help uncover any lingering security issues that may have not been considered during the implementation and deployment phases.
Hopefully this article will provide some clarity and guidance on these topics, which can be hard to tackle. Stay tuned for more articles diving deeper into fintech and open banking application and API security.
If you have any additional questions and/or comments feel free to reach out to us.
Disclaimer: the information presented in this article is for educational purposes only. By no means we imply this solution to be the definitive secure architecture for this problem, as each context will have its particularities, and it would need to be adapted for each particular case.